
Warum reguläre Ausdrücke?
In der technischen Dokumentation und Übersetzung stehen wir oft vor der Herausforderung, große Textmengen effizient zu bearbeiten: Produktbezeichnungen müssen standardisiert, Formatierungen vereinheitlicht und Übersetzungen konsistent gehalten werden. Reguläre Ausdrücke (kurz: Regex) sind dabei ein mächtiges Werkzeug, das diese Aufgaben erheblich erleichtert. Stellen Sie sich Regex als eine Art Schweizer Taschenmesser für Textbearbeitung vor – vielseitig einsetzbar und unglaublich nützlich, wenn man weiß, wie man damit umgeht.
Besonders wertvoll sind reguläre Ausdrücke für:
- Die Standardisierung technischer Dokumentation
- Die Qualitätssicherung von Übersetzungen
- Die Automatisierung wiederkehrender Textarbeiten
- Die Verarbeitung großer Dokumentmengen
Dieser Artikel zeigt Ihnen, wie Sie reguläre Ausdrücke in Ihrer täglichen Arbeit als technischer Redakteur oder Übersetzer einsetzen können, um Zeit zu sparen und die Qualität Ihrer Dokumente zu verbessern.
1. Grundlegendes zu regulären Ausdrücken
Reguläre Ausdrücke sind Zeichenfolgen, die als Suchmuster für Text dienen. Sie ermöglichen es, komplexe Textmuster zu finden und zu bearbeiten. Denken Sie an eine erweiterte “Suchen und Ersetzen”-Funktion, die nicht nur nach exakten Wörtern sucht, sondern nach Mustern wie “alle Zahlen mit einer Einheit” oder “alle E-Mail-Adressen”.
Die wichtigsten Elemente von Regex
Lassen Sie uns die grundlegenden Bausteine kennenlernen:
Zeichen und ihre Bedeutung:
- \d findet jede Ziffer (0-9)
- \w findet jeden Buchstaben, jede Ziffer und Unterstriche
- . findet jedes beliebige Zeichen außer Zeilenumbrüche
- * bedeutet “null oder mehr Vorkommen”
- + bedeutet “ein oder mehr Vorkommen”
Beispiele
- Alle Zahlen abgleichen: \d+
- Dieses Muster sucht nach einer oder mehreren aufeinanderfolgenden Ziffern.
- E-Mail-Adressen abgleichen: \w+@\w+\.\w+
- Dieses Muster sucht nach einer einfachen E-Mail-Adresse, die aus alphanumerischen Zeichen, einem @-Zeichen, einem Domainnamen und einer Top-Level-Domain besteht.
2. Regex für die Standardisierung technischer Dokumentation
Standardisierung von Formaten und Abkürzungen
Für Autoren ist es wichtig, eine einheitliche Verwendung von Datum, Zahlen und Abkürzungen sicherzustellen. Regex können verwendet werden, um diese Formate in einem Text zu standardisieren und sicherzustellen, dass der Text konsistent und professionell wirkt. Die Standardisierung von Texten unterstützt außerdem den Übersetzungsprozess.
Formulierungen in Texten vereinheitlichen
Regex können auch verwendet werden, um komplexe bzw. uneinheitliche Formulierungen oder Jargon automatisch zu ersetzen. Dies kann die Lesbarkeit und Verständlichkeit eines Textes erheblich verbessern und sicherstellen, dass der Text für die Zielgruppe zugänglich ist. Betrachten wir dieses konkrete Beispiel mit verschiedenen Schreibweisen in einem Dokument:
Bahnenbezeichnung gemäß DIN SPEC 20000-201
Bahnenbezeichnung nach DIN SPEC 20000-201
Bahnenbezeichnung nach DIN SPEC 20000-201
Mit diesem regulären Ausdruck können wir die Schreibweisen vereinheitlichen:
- Suchen nach: ^Bahnenbezeichnung (gemäß|nach) DIN
- Ersetzen durch: Bahnenbezeichnung nach DIN
Textanalyse mit Regex unterstützen
Autoren können Regex verwenden, um Schlüsselbegriffe oder sich wiederholende Muster in großen Texten zu identifizieren. Dies kann nützlich sein, um Daten für die Analyse zu extrahieren und Einblicke in den Text zu gewinnen. Ein praktisches Beispiel: Ein technischer Redakteur könnte mit einem Regex-Muster wie "(Achtung|Warnung|Vorsicht).+" alle Sicherheitshinweise in einem Handbuch finden. Dies ermöglicht es ihm zu prüfen, ob die Warnungen einheitlich formuliert sind und ob sie allen Richtlinien entsprechen.
Vereinheitlichung von Produktbezeichnungen
Ein häufiges Problem in der technischen Dokumentation ist die uneinheitliche Schreibweise von Produktbezeichnungen, wie: Hochdruckreiniger Plus 3000 / Hochdruck-Reiniger Plus 3000 / Hochdruckreiniger plus3000 usw.
Standardisierung von Temperatur- oder Massangaben
Auch bei Temperaturangaben finden sich oft verschiedene Schreibweisen:
- mindestens + 5 °C
- ab + 5 °C
- ab +5 °C
Dieser reguläre Ausdruck findet alle Varianten: (mindestens|ab)\s*\+\s*(\d+)\s*°C
Ersetzen durch: ab +$2 °C
Korrektur von PDF-Konvertierungsfehlern
Bei der Konvertierung von PDF-Dokumenten entstehen oft typische Fehler wie unerwünschte Zeilenumbrüche. Beispiel:
Die zweite Person zieht die Trenn-
folie schräg in Längsrichtung ab.
Dieser reguläre Ausdruck korrigiert getrennte Wörter: (\w+)-\s*\n(\w+)
Ersetzen durch: \$1\$2
3. Regex in der Übersetzungsarbeit
Vor der Übersetzung
Extraktion von Terminologie
Regex können auch verwendet werden, um Fachbegriffe, Akronyme, Softwarestrings oder Produktbezeichnungen in einem Text zu identifizieren. Dies ist besonders nützlich für die Erstellung von Glossaren oder Terminologiedatenbanken, die für konsistente Übersetzungen unerlässlich sind.
Auch in XML- oder HTML-Dateien können Regex verwendet werden, um auf Basis von Regeln Terminologie zu extrahieren, z.B. Termini in Anführungszeichen, Artikelbezeichnungen oder zwischen bestimmten Tags.

Regex sind auch nützlich, um die Schreibweise von Termini zu standardisieren, bevor sie in eine Terminologiedatenbank importiert werden. Der angezeigte Ausdruck (siehe Screenshot) stellt sicher, dass alle spanischen Termini in Kleinbuchstaben geschrieben werden.
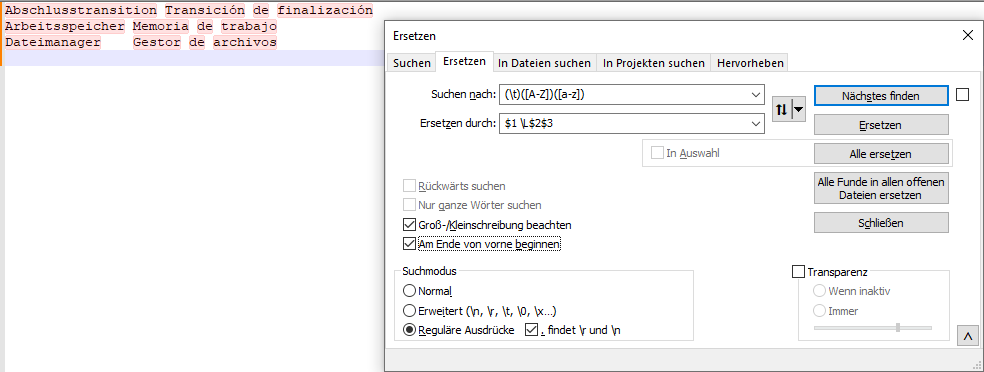
Ergebnis:
- Abschlusstransition <TAB> transición de finalización
- Arbeitsspeicher <TAB> memoria de trabajo
- Dateimanager <TAB> gestor de archivos
Suche mit Regex
Bei der Suche im Überprüfungsfenster von Trados helfen Regexes auch beim Filtern von Segmenten mit bestimmten Merkmalen, z. B. von Segmenten, die Zahlen enthalten.
Andere Tools, die Teil der Arbeitsumgebung von Übersetzern sind, wie z. B. ErrorSpy oder XBench, unterstützen ebenfalls reguläre Ausdrücke.
Qualitätssicherung von Übersetzungen
Regex sind besonders nützlich bei der Qualitätskontrolle:
- Überprüfung der korrekten Übernahme von Zahlen und Einheiten
- Sicherstellung einheitlicher Terminologie
- Erkennung typischer Übersetzungsfehler
Beispiel für die Überprüfung von Maßeinheiten: \d+(\,\d+)?\s*(mm|cm|m)
Dieser Ausdruck findet alle Längenangaben und hilft bei der Kontrolle der korrekten Übernahme.
4. Verwendung von Regex in Microsoft Word
Microsoft Word wird häufig als Textverarbeitungsprogramm verwendet. Es unterstützt keine klassischen regulären Ausdrücke, bietet aber Wildcards, die viele Muster erkennen. Erkannte Zeichenfolgen können z.B. ersetzt oder hervorgehoben werden.
So gehen Sie vor, um Wildcards zu verwenden:
- Öffnen Sie “Ersetzen” (Strg+H)
- Klicken Sie auf “Mehr >>”
- Aktivieren Sie das Kontrollkästchen „Platzhalter verwenden“.
Beispiele für Wildcard-Muster in Word
- Suchen Sie alle Wörter, die mit „Fahr“ beginnen: <Fahr*
- Dieses Muster sucht nach allen Wörtern, die mit „Fahr“ beginnen, wie z.B. „Fahrt“, „Fahrzeug“ usw.
- Zahlen in Klammern ersetzen: ([0-9]{1;}) → Ersetzen durch (\1)
- Dieses Muster sucht nach Zahlen in Klammern und ersetzt sie durch die gleichen Zahlen in Klammern.
- Doppelte Leerzeichen durch einfache ersetzen: [Leerzeichen] {2;} → [Nur ein Leerzeichen]
- Dieses Muster sucht nach doppelten Leerzeichen und ersetzt sie durch einfache Leerzeichen.
5. Praktische Tools für Regex
Online-Tools zum Testen und Lernen von Regex
- Regex101: https://regex101.com/
- Regex101 ist ein leistungsfähiges Online-Tool zum Testen und Lernen von Regex. Es bietet eine benutzerfreundliche Oberfläche und detaillierte Erklärungen zu den verwendeten Mustern.
- Regexr: https://regexr.com/
- Regexr ist ein weiteres nützliches Online-Tool, das eine interaktive Benutzeroberfläche bietet, um Regex zu testen und zu lernen.
Texteditoren mit Regex-Unterstützung
- Notepad++:
- Notepad++ ist ein beliebter Texteditor, der umfangreiche Regex-Unterstützung bietet. Es ist besonders nützlich für die Bearbeitung großer Textdateien.
- UltraEdit:
- UltraEdit ist ein weiterer leistungsfähiger Texteditor mit Regex-Unterstützung. Es bietet eine Vielzahl von Funktionen und Erweiterungen, die die Arbeit mit Regex erleichtern.
- Visual Studio Code:
- Visual Studio Code ist ein beliebter Code-Editor, der umfangreiche Regex-Unterstützung bietet. Es ist besonders nützlich für Entwickler und Autoren, die mit großen Codebasen oder Textdateien arbeiten.
CAT-Tools, die Regex unterstützen
- Trados Studio:
- Trados Studio ist ein beliebtes CAT-Tool, das umfangreiche Regex-Unterstützung bietet. Es ermöglicht Übersetzern, benutzerdefinierte Segmentierungsregeln zu erstellen und nicht übersetzbare Elemente zu schützen.
- memoQ:
- memoQ ist ein weiteres leistungsfähiges CAT-Tool, das Regex-Unterstützung bietet. Es ermöglicht Übersetzern, komplexe Such- und Ersetzungsoperationen durchzuführen und die Konsistenz ihrer Übersetzungen sicherzustellen.
- Across:
- Across ist ein weiteres CAT-Tool, das Regex-Unterstützung bietet. Es ermöglicht Übersetzern, ihre Arbeit effizienter zu gestalten und die Qualität ihrer Übersetzungen zu verbessern.
6. Regex-Dialekte: Was Sie wissen müssen
Regex-Implementierungen unterscheiden sich geringfügig zwischen verschiedenen Tools und Programmiersprachen. Diese Unterschiede können zu Kompatibilitätsproblemen führen, wenn Sie Regex in verschiedenen Umgebungen verwenden. Es ist wichtig, diese Nuancen zu kennen, um solche Probleme zu vermeiden.
Gängige Regex-Dialekte
- Perl-kompatible reguläre Ausdrücke (PCRE):
- PCRE werden in vielen modernen Tools wie PHP, Python und Notepad++ verwendet. Sie bieten eine Vielzahl von Funktionen und sind sehr leistungsfähig.
- JavaScript Regex:
- JavaScript Regex sind ähnlich wie PCRE, bieten jedoch nicht alle erweiterten Funktionen, wie z.B. Lookbehinds.
- Microsoft Word Regex (Wildcards):
- Microsoft Word bietet eine eingeschränkte Regex-Funktionalität, die als Wildcards bekannt ist. Diese sind nur in Word verfügbar und bieten grundlegende Funktionen.
7. Datenbereinigung mit Regex im Zeitalter des maschinellen Lernens
Warum Datenbereinigung so wichtig ist
Hochwertige, konsistente Daten sind für das Training von Modellen für maschinelles Lernen und die Gewährleistung einer genauen Analyse unerlässlich. Regex können verwendet werden, um Daten zu bereinigen und sicherzustellen, dass sie für die Analyse geeignet sind.
Anwendungen von Regex bei der Datenbereinigung
- Entfernen von Duplikaten oder unnötigen Leerzeichen: ^\s+|\s+$
- Dieses Muster entfernt führende und nachstehende Leerzeichen in einem Text.
- Normalisierung von Text:
- Regex können verwendet werden, um Text zu normalisieren, z.B. die Umwandlung von Jan 1, 2024 in 01-01-2024.
- Erkennen und Korrigieren von Formatierungsinkonsistenzen in Datensätzen:
- Regex können verwendet werden, um Formatierungsinkonsistenzen in Datensätzen zu erkennen und zu korrigieren, wie z.B. die Umwandlung von 2.000,00 Euro in Euro 2.000,00.
- Bereinigung mehrsprachiger Korpora oder von Translation-Memorys:
- Regex können verwendet werden, um mehrsprachige Korpora zu bereinigen, bevor sie für das Training von KI-Modellen verwendet werden. Sie können u.a. für die Anonymisierung von Daten eingesetzt werden.
8. Fortgeschrittene Regex-Techniken für Power-User
Greedy vs. Lazy Matching
- Greedy Matching:
- Greedy Matching bedeutet, dass das Regex-Muster so viel Text wie möglich abgleicht. Dies kann zu unerwarteten Ergebnissen führen, wenn das Muster zu allgemein ist.
- Lazy Matching:
- Lazy Matching bedeutet, dass das Regex-Muster so wenig Text wie möglich abgleicht. Dies kann verwendet werden, um genauere Ergebnisse zu erzielen. Lazy Matching wird durch das Anhängen von ? an einen Quantor erreicht, z.B. *?.
Rückverweise
- Verwendung erfasster Gruppen:
- Rückverweise ermöglichen es, auf vorherige Übereinstimmungen zu verweisen. Dies kann nützlich sein, um komplexe Muster zu erstellen, die auf vorherigen Übereinstimmungen basieren. Zum Beispiel erkennt der Ausdruck \b(\w+)\s+\1\b doppelte Wörter (d. h. Verweis auf eine vorhergehende Übereinstimmung).
Lookahead und Lookbehind
Mit Lookahead und Lookbehind überprüft der Ausdruck nicht nur das Muster selbst, sondern auch den Kontext. Nur wenn ein bestimmter Ausdruck vor oder nach dem gesuchten Ausdruck erscheint, wird der gesuchte Ausdruck angezeigt und gegebenenfalls ersetzt. Nicht alle „Regex-Dialekte“ unterstützen diese Option.
-
- Lookahead und Lookbehind: Lookahead und Lookbehind ermöglichen es, sicherzustellen, dass ein Muster in einem bestimmten Kontext erscheint, ohne diesen Kontext selbst zu erfassen. Dies ist nützlich, um komplexere Suchmuster zu erstellen.
-
- Positiver Lookahead: X(?=Y) Findet X, wenn unmittelbar danach Y folgt. Beispiel: \d+(?= Euro) findet Zahlen vor „Euro“.
- Negativer Lookahead: X(?!Y) Findet X, wenn nicht unmittelbar danach Y folgt. Beispiel: \d+(?! USD) findet Zahlen, die nicht vor „USD“ stehen.
- Positiver Lookbehind: (?<=Y)X Findet X, wenn unmittelbar davor Y steht. Beispiel: (?<=Artikel )\d+ findet Zahlen nach „Artikel“.
- Negativer Lookbehind: (?<!Y)X Findet X, wenn nicht unmittelbar davor Y steht. Beispiel: (?<!Seite )\d+ findet Zahlen, die nicht nach „Seite“ stehen.
-
- Lookahead und Lookbehind: Lookahead und Lookbehind ermöglichen es, sicherzustellen, dass ein Muster in einem bestimmten Kontext erscheint, ohne diesen Kontext selbst zu erfassen. Dies ist nützlich, um komplexere Suchmuster zu erstellen.
Unicode-Eigenschaften und Blockbereiche
Mit regulären Ausdrücken lassen sich auch Unicode-Eigenschaften nutzen, um Zeichen bestimmter Kategorien zu erfassen. Dies ist besonders hilfreich, wenn Sie internationalisierte Texte verarbeiten, die Buchstaben, Symbole oder Zeichen aus verschiedenen Sprachen enthalten. Allerdings unterstützen nicht alle Regex-Dialekte diese Funktion.
Beispiele für Unicode-Eigenschaften
- \p{L}: Erfasst alle Buchstaben unabhängig von der Sprache (z. B. Latein, Kyrillisch, Arabisch).
- \p{Ll}: Erfasst alle Kleinbuchstaben.
- \p{Lu}: Erfasst alle Großbuchstaben.
- \p{P}: Erfasst alle Satzzeichen.
Beispiel: Suche nach chinesischen Zeichen
Um alle chinesischen Schriftzeichen zu extrahieren, die im Unicode-Block CJK Unified Ideographs liegen, verwenden Sie folgenden Ausdruck:
[\p{Script=Han}]
Dieser Ausdruck erfasst sämtliche chinesischen Zeichen. Er ist besonders nützlich, wenn Sie Texte analysieren möchten, die mehrsprachige Inhalte enthalten.
9. Tipps und bewährte Verfahren für die Verwendung von Regex
Schrittweises Vorgehen
- Beginnen Sie mit einem kleinen Textausschnitt
- Testen Sie Ihren Regex-Ausdruck gründlich
- Dokumentieren Sie erfolgreiche Ausdrücke für spätere Verwendung
- Erstellen Sie sich eine persönliche Bibliothek bewährter Ausdrücke
Gehen Sie auf Nummer sicher
- Erstellen Sie immer eine Sicherungskopie vor größeren Änderungen
- Testen Sie Regex-Ausdrücke zunächst an einer kleinen Textmenge
- Nutzen Sie die “Alle suchen”-Funktion vor dem “Alle ersetzen”
Fazit: Der Einfluss von Regex auf Produktivität und Qualität
Regex sind ein leistungsfähiges Werkzeug, das die Produktivität von Übersetzern und Autoren erheblich steigern kann. Der Einstieg ist natürlich nicht so einfach, aber jede Reise beginnt mit einem ersten Schritt. Durch die Automatisierung wiederkehrender Aufgaben und die Sicherstellung der Konsistenz und Genauigkeit von Texten können Regex Zeit sparen und die Qualität der Arbeit verbessern.