Ein Vierteljahrhundert voller Innovation und Kundenorientierung
Im April feiert die D.O.G. GmbH ihr 25-jähriges Bestehen. Zu diesem Anlass werfen wir einen Blick auf die Entwicklungen in der Übersetzungsbranche und unsere Rolle in diesem Wandel. Gegründet 1999, als die Welt noch ganz anders aussah, hat sich die D.O.G. GmbH von einem kleinen Start-up mit drei Mitarbeitern zu einem etablierten Unternehmen in der Übersetzungsbranche entwickelt.
Langjährige Kunden
Viele ihrer Kunden betreut die D.O.G. GmbH bereits seit zehn Jahren oder länger. Das Unternehmen zeichnet sich durch seine hohe Kundenzufriedenheit und seinen Fokus auf Qualität aus.
Mitarbeiter als Schlüssel zum Erfolg
Neben den Kunden sind es vor allem die Mitarbeiter, die zum Erfolg der D.O.G. GmbH beigetragen haben. Viele Kolleginnen und Kollegen sind seit den Anfängen dabei und haben mit ihrem Engagement und ihrer Expertise die Entwicklung des Unternehmens maßgeblich mitgestaltet. Das trifft auch auf unsere freiberuflichen Übersetzer zu, von denen viele schon seit einem Jahrzehnt oder länger mit uns zusammenarbeiten.
Technologischer Wandel
In den letzten 25 Jahren hat die Übersetzungsbranche erhebliche Veränderungen erlebt. Besonders prägend waren das Aufkommen der Translation-Memory-Technologien in den 1990er Jahren und die Verbreitung maschineller Übersetzungssysteme in den 2010er Jahren.
Diese Innovationen sind aus der Notwendigkeit entstanden, Übersetzungen effizienter zu verwalten. Mit der Erweiterung der EU wuchs auch der Bedarf an technischen Lösungen, um die steigenden Übersetzungsvolumen und -kosten zu bewältigen. Es wurde notwendig, mehrere neue Sprachen zu unterstützen. Die vierte Erweiterung der EU fand mit dem Beitritt von Österreich, Finnland und Schweden im Jahr 1995 statt. Diese 15 Mitgliedstaaten wurden 2004 von zehn weiteren Ländern, den osteuropäischen Ländern, ergänzt, die weitere Sprachen in die EU brachten. Gleichzeitig haben der globale Wettbewerb und die kürzeren Produktionszyklen in der Industrie die Nachfrage nach computergestützter Übersetzung (CAT) angekurbelt. Der Übersetzungssektor erhielt 2006 einen wichtigen Impuls durch die EU-Maschinenrichtlinie 2006/42/EG, die die Übersetzung von Produktdokumentationen in die Landessprache eines EU-Landes verlangte.
Meilensteine der vergangenen 25 Jahre
1990er: Aufkommen von Translation-Memory-Technologien
Computerunterstützte Übersetzungssysteme (CAT-Systeme) waren bereits in den frühen 1980er Jahren bekannt. Sie erschienen zuerst in den USA mit dem TSS (Translation Support System), dem ersten kommerziellen Tool der damaligen Firma ALPS (Automated Language Processing Systems). Kurz darauf gründeten 1984 Jochen Hummel und Iko Knyphausen das Übersetzungsunternehmen Trados im Raum Stuttgart und stellten 1994 das Übersetzungsprogramm Translator’s Workbench (TWB) vor. Die ersten übersetzten Dateien waren zweisprachige RTF-Dateien, und die fertige Übersetzung musste durch einen Prozess namens ” Clean-up ” (Entfernung von Tags und der Ausgangssprache) erstellt werden. Weitere Anbieter folgten: Déjà-Vu, TRANSIT, SDLX, IBM TM/2.

Während die Nachfrage nach CAT-Tools langsam stieg, waren diese Technologien bei Übersetzern noch nicht weit verbreitet. Eine Studie des britischen ITI schätzte, dass im Jahr 1999 nur 15 % der Übersetzer CAT-Tools einsetzten. Diese Technologien kosteten Geld und einige Übersetzer waren der Meinung, dass sie sich negativ auf die Qualität ihrer Arbeit auswirken würden. Diese damalige Anzeige im Übersetzerforum proz.com zeigt, dass CAT-Tools noch recht teuer waren: “Ich verkaufe Trados 1.0, einschließlich Multiterm 95, mit Dongle und englischen Handbüchern. Ich zahlte 1997 4.000 Mark dafür.” Es war daher für Übersetzungsbüros und Kunden schwierig, für einige Sprachkombinationen und Fachgebiete Übersetzer zu finden, die über ein Translation Memory-Programm verfügten.
D.O.G. GmbH entwickelte deshalb ein Add-On für Microsoft Word namens TransDOG, das es Übersetzern ermöglichte, ihre Übersetzungen effizient zu speichern und wiederzuverwenden. Die Übersetzungsspeichertechnologie ermöglichte es der D.O.G. GmbH, bereits übersetzte Textsätze in neuen Projekten wiederzuverwenden. Dies führte zu einer Steigerung der Effizienz und Qualität der Übersetzungen.
2000er: Dateiformate und Schriftsätze
In den frühen 2000er Jahren war die Welt der Dokumentenerstellung sehr unterschiedlich. Layout-Systeme wie Interleaf, QuarkXpress, Ventura und Pagemaker dominierten den Sektor, während Word-Prozessoren wie Word6, WordPerfect und Lotus 1-2-3 immer noch für die Textverarbeitung verwendet wurden.
Einige Dokumentationen wurden in Auszeichnungssprachen wie SGML erstellt, während XML noch in den Kinderschuhen steckte.
Diese Vielfalt an Formaten und Systemen stellte Übersetzer und Redakteure vor große Herausforderungen, insbesondere wenn sie mit Fremdsprachen arbeiteten. Da Unicode noch nicht weit verbreitet war, gab es oft Probleme mit Sonderzeichen und Schriftarten, die nicht von allen Sprachen unterstützt wurden. Dies führte regelmäßig zu Schwierigkeiten, insbesondere bei den “östlichen Sprachen” und den asiatischen Sprachen.
Einführung von Redaktionssystemen
Die 2000er Jahre brachten neue Herausforderungen mit sich. In den frühen 2000er Jahren war die Erstellung von Dokumenten für einen Großteil der Unternehmen ein manueller Prozess: einzelne Kapitel oder wiederverwendbare Informationen befanden sich in verschiedenen Dateien, die dann je nach Produktvariante zusammengestellt wurden. Dies war zeitaufwendig und fehleranfällig. Redaktionssysteme oder Content Management Systeme (CMS) waren die Antwort. Sie ermöglichten es, technische Dokumentationen strukturiert zu erstellen und zu verwalten. Dies erleichterte die Übersetzung und Aktualisierung der Dokumente.
Die Verbreitung von Redaktionssystemen ging Hand in Hand mit der Optimierung der Texterstellung. Um den vollen Nutzen aus standardisierten Prozessen und der Wiederverwendung zu ziehen, wurde der Schwerpunkt auf kontrollierte Sprache gelegt. Die Regeln für die Formulierung und den Schreibstil wurden in Redaktionsleitfäden festgehalten, um konsistente und wiederverwendbare Texte zu gewährleisten.
Damit wurde der Trend in der Industrie deutlich: fragmentierte arbeitsteilige Prozesse, Maximierung der Wiederverwendung von Inhalten und Übersetzungen.
Der Bedarf an Qualitätssicherungstechnologien
Anfang der 2000er Jahre erkannten wir, dass die zunehmend fragmentierten Prozesse bei der Erstellung mehrsprachiger Dokumentationen eine teilweise Automatisierung der Qualitätssicherung erfordern: In Translation Memories werden Sätze gespeichert, die von verschiedenen Übersetzern zu unterschiedlichen Zeitpunkten erstellt wurden (Stil und Terminologie sind nicht immer identisch). In ähnlicher Weise speichern verschiedene Redakteure ihre Texte auf modulare Weise in einem CMS.
Neue Dokumentationen werden aus verschiedenen Quelltextmodulen erstellt oder kombiniert und mit Hilfe von Übersetzungsspeichern vorübersetzt. Es ist daher zunehmend notwendig, genauer zu überprüfen, ob alle (Autoren und Übersetzer) die gleiche Sprache verstehen und produzieren. Aus diesem Grund haben wir 2003 unsere Qualitätssicherungssoftware ErrorSpy auf den Markt gebracht, die erste kommerzielle Qualitätssicherungssoftware für Übersetzungen.
Da die Terminologie eine wichtige Rolle für die Qualität der Übersetzung spielt, war es notwendig, den Prozess der Terminologieextraktion zu unterstützen. Dies war der Ausgangspunkt für unser erstes Programm zur Terminologieextraktion, TermiDOG, das wir 2001 herausbrachten und bei vielen Übersetzern beliebt wurde. Heute haben wir eine statistische und linguistische Terminologieextraktion in LookUp integriert.
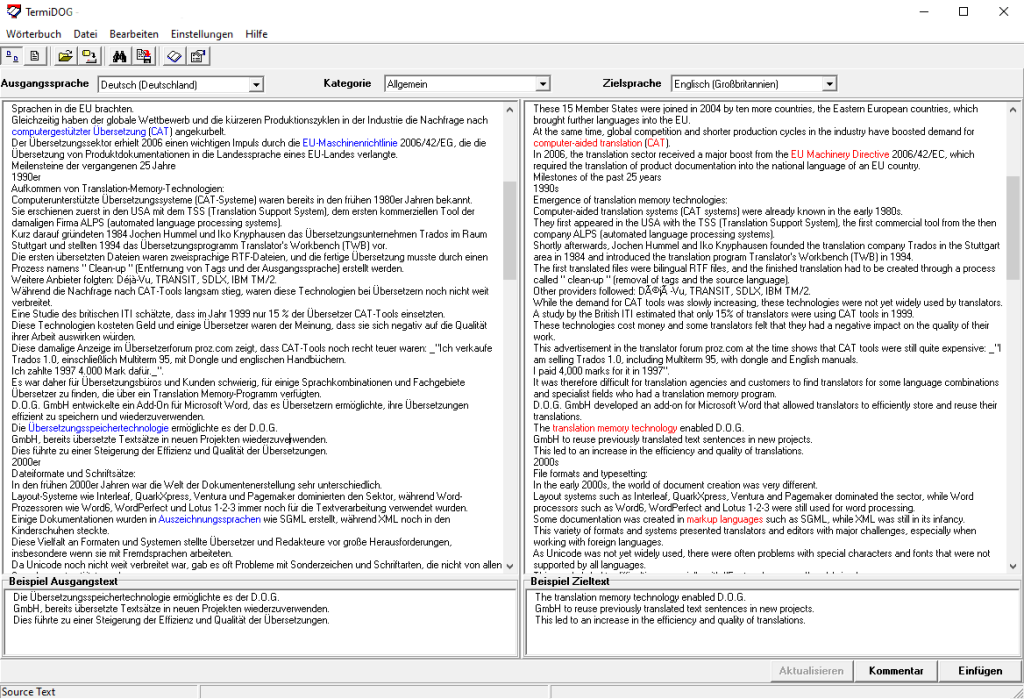
Ein paar Jahre nach ErrorSpy, im Jahr 2007, haben wir auch unser Terminologieverwaltungstool LookUp eingeführt, um eine konsistente und klar definierte Terminologie zu verwenden.
2010er: Die Anfänge der maschinellen Übersetzung
Die Anfänge der maschinellen Übersetzung reichen weit zurück. Ursprünglich liefen die ersten, noch schwerfälligen Systeme auf Großrechnern und waren damit für viele Übersetzer unzugänglich.
Die 90er Jahre brachten den ersten Hoffnungsschimmer für automatische Übersetzungen: Statistische maschinelle Übersetzungssysteme (MÜ) wie Systran kamen auf den Markt. Die Qualität war jedoch enttäuschend. Die Systeme lieferten oft sinnentleerte oder grammatikalisch falsche Übersetzungen, die eine teure Nachbearbeitung erforderten.
Einige Auftraggeber und Übersetzungsdienstleister begannen in den 2000er Jahren, maschinelle Übersetzungsprojekte einzusetzen, aber dies blieb für viele Jahre die Ausnahme.
Auch die D.O.G. GmbH interessierte sich für diese Technologien und startete 2008 ein Forschungsprojekt mit dem Titel “Enhancing Machine Translation Quality with ErrorSpy” mit dem ISIT in Paris.
Die maschinelle Übersetzung startete erst Jahre später auf breiterer Basis mit der Entwicklung von neuronalen Systemen für maschinelle Übersetzung (NMT). Google Translate war einer der Vorreiter im Jahr 2016 und kurz danach DeepL, aber auch hier waren die Ergebnisse mit Vorsicht zu genießen.
Erst in den letzten Jahren hat sich die Qualität von NMTs deutlich verbessert, so dass sie in einer Vielzahl von Anwendungsfällen in Kombination mit Post-Editing (professionelle Nachbearbeitung durch einen menschlichen Übersetzer) eingesetzt werden können.
Entwicklung von cloudbasierten Lösungen
Mit der zunehmenden Digitalisierung, der Verfügbarkeit von sicheren Datenaustauschmöglichkeiten und schnelleren Internetverbindungen in den 2010er Jahren haben sich cloudbasierte Lösungen auch in der Übersetzungsbranche etabliert. Die D.O.G. GmbH erkannte schnell das Potenzial dieser Technologie und nahm sie in ihr Produktangebot auf.
Ein wichtiger Schritt war die Einführung des Kundenportals. Dieses webbasierte Tool ermöglicht es Kunden, Übersetzungsprojekte online in Auftrag zu geben, den Fortschritt zu verfolgen und mit dem Team von D.O.G. zu kommunizieren.
Ein weiterer Schritt in Richtung Cloud war die Entwicklung von LookUp im Jahr 2007, das zur Verwaltung von Terminologie in der Cloud eingesetzt wird. Dieses Tool ermöglicht die Zusammenarbeit zwischen verteilten Teams und Spezialisten bei der Verwaltung von technischen Begriffen und Terminologie.
Neben den traditionellen Desktop-basierten Übersetzungsprogrammen wurden in dieser Zeit webbasierte Übersetzungstechnologien entwickelt, bei denen Sprachressourcen (hauptsächlich Translation Memories und Terminologie) in der Cloud gespeichert und verwaltet werden. Ein Beispiel dafür ist der “Translation Workspace” von Lionbridge, der auf Logoport basiert und bereits 2005 eingeführt wurde. Heute bieten viele Entwickler von Übersetzungstechnologien eine Cloud-Version ihrer Produkte an.
Des Weiteren betrieben einige wenige internationale Sprachdienstleister in dieser Zeit Crowdsourcing-Plattformen, also Plattformen, auf denen Zehntausende von Übersetzern aus aller Welt ihre Dienste anbieten.
2020er: Die Ära der KI und der großen Sprachmodelle (LLMs)
Generative KI und Large Language Models (LLMs) revolutionieren die technische Kommunikation seit etwa 2023 grundlegend. Diese fortschrittlichen Technologien “verstehen” den Inhalt von Texten und generieren Texte, was eine Vielzahl neuer Möglichkeiten eröffnet. Die D.O.G. GmbH nutzt bereits das Potenzial der KI, um die Qualität der Übersetzungen und die Effizienz ihrer Dienstleistungen zu verbessern.
Einerseits verbessern LLMs die Qualitätssicherung, indem sie semantische oder stilistische Fehler in Texten erkennen und so zur Verbesserung der Qualität von Übersetzungen beitragen. Andererseits können sie selbständig Texte in verschiedenen Sprachen erstellen, z. B. Metadaten oder Produktbeschreibungen. Dies reduziert den Zeitaufwand und die Kosten, die mit traditionellen Übersetzungsmethoden verbunden sind.
Darüber hinaus erleichtern LLMs das Terminologiemanagement, indem sie Fachbegriffe ermitteln und definieren, was die Erstellung und Pflege von Terminologiedatenbanken vereinfacht. Dies ist besonders wertvoll in Fachgebieten, in denen eine genaue und einheitliche Terminologie von entscheidender Bedeutung ist.
KI als Chance für die Zukunft
Entgegen der Befürchtung, dass KI menschliche Übersetzer ersetzen könnte, betrachtet die D.O.G. GmbH KI als einen Partner, der die menschlichen Fähigkeiten ergänzt. Während Menschen ihre Kreativität und ihr Stilgefühl einbringen, übernimmt die KI Aufgaben, die sie effizienter oder genauer ausführen kann, wie z.B. die schnelle Suche in großen Datenmengen oder die Einhaltung einer konsistenten Terminologie.
Fazit: 25 Jahre D.O.G. – Innovation und Tradition in Einklang
Seit 25 Jahren beweist D.O.G. GmbH Weitblick und Innovationsgeist, um sich erfolgreich an die sich ändernden Bedürfnisse der Übersetzungsbranche anzupassen. Von den Anfängen der computergestützten Übersetzung bis hin zu cloudbasierten Lösungen und maschinellen Übersetzungen hat D.O.G. GmbH immer die richtige Richtung eingeschlagen und war mit Entwicklungen wie ErrorSpy ein Vorreiter.
Heute setzt die D.O.G. GmbH aktiv auf KI-basierte Lösungen, um ihren Kunden individuelle und effiziente Übersetzungsprozesse zu bieten. Die Kombination aus Tradition, Erfahrung und zukunftsorientierter Technologie macht D.O.G. GmbH zu einem zuverlässigen Partner für Unternehmen, die nach leistungsstarken Lösungen für die Übersetzung ihrer Fachtexte suchen.
Im Rückblick auf ein Vierteljahrhundert voller Errungenschaften und im Blick nach vorn auf eine Zukunft voller Möglichkeiten, möchten wir unseren Kunden, unserem Team und unseren Partnern danken. Die Reise geht weiter, und wir sind stolzer denn je, sie gemeinsam zu gestalten.