
Schreiben für Maschinen, oder maschinengerechtes Schreiben, ist ein relativ neues Thema. Warum Maschinen für den Informationsaustausch wichtig geworden sind und was sie heute leisten können, erfahren Sie im folgenden Artikel.
A: Mit maschinellen Übersetzungsprogrammen können Benutzer Dokumente ohne menschliche Hilfe von einer Sprache in eine andere übersetzen. Diese Programme haben jedoch ihre Nachteile und können ernsthafte Probleme verursachen, wenn sie nicht richtig verwendet werden.
B: Heutzutage können neuronale Programme maschineller Übersetzung als Basis für professionelle Übersetzungen eingesetzt werden.
Können Sie, wenn Sie die obigen beiden Sätze lesen, unterscheiden, welchen Satz eine Maschine und welchen ein Mensch geschrieben hat[1]? Antwort: den ersten Text hat eine Maschine geschrieben.
Es ist manchmal erstaunlich, wie gut und wie nah an der Leistung eines Menschen, Maschinen heute Sprache verstehen und verarbeiten können.
Die meisten Artikel, Checklisten oder Empfehlungen zur Textoptimierung fokussieren jedoch hauptsächlich auf Texte, die für Menschen bestimmt sind. Künstliche Intelligenz gepaart mit natürlicher Sprachverarbeitung (Natural Language Processing , NLP) und natürlichem Sprachverständnis (Natural Language Understanding , NLU) dringt nun in immer mehr Bereiche unseres Lebens ein. Menschen und Maschinen produzieren Informationen gemeinsam und beeinflussen sich gegenseitig. Diese Zusammenarbeit mag nicht immer explizit sein, aber sie ist bereits ein unauffälliger Teil des Alltags von technischen Redakteuren und Übersetzern.
Ohne KI, ohne Suchmaschinen, ohne Schreibhilfen, ohne die vielen KI-gestützten Funktionen von Anwendungen, die die Arbeit von Redakteuren oder Übersetzern unterstützen, wäre die technische Kommunikation in der heutigen Form kaum noch vorstellbar. Maschinengerechtes Schreiben ist daher angesagt.
Was versteht man unter Maschine?
Was sind das für Maschinen, von denen hier die Rede ist, und was können sie? Wir verwenden das Wort „Maschine“ im Sinne eines mathematischen Modells der Sprache, das eine Anwendung verwendet, um die Sprache zu verstehen und zu verarbeiten.
Derartige Modelle werden zuerst von Maschinen erlernt und sind zweckgebunden, d. h. ein Modell für die maschinelle Übersetzung zwischen Deutsch und Englisch sieht anders aus als ein Modell für die maschinelle Übersetzung zwischen Deutsch und Französisch oder für die Zusammenfassung von Texten.
Diese Modelle werden mit großen Datenmengen (Big Data genannt) trainiert. Ein größeres Modell wie das GPT-3 Sprachmodell von OpenAI lernte die Sprache mit einem Korpus von fast 500 Milliarden Wörtern. Sobald sie trainiert sind, können Anwendungen wie ein maschinelles Übersetzungssystem auf ein Modell zurückgreifen, um Sprache zu verarbeiten. Zum Beispiel um neue, ungesehene Texte zu übersetzen.
Welche intelligenten Systeme gibt es?
Intelligente Systeme, die natürliche Sprache verstehen, sind bereits heute in sehr unterschiedlichen Bereichen zu finden. Neben der neuronalen maschinellen Übersetzung wie bei Google Translate oder DeepL gibt es Systeme, die Informationen aus sehr großen Korpora extrahieren, Chatbots, die Fragen beantworten, Anwendungen, die Texte klassifizieren, neue Texte schreiben oder Sprache in Text umwandeln, und vieles mehr.
Was uns hier aber vordergründig interessiert, sind maschinelle Übersetzungen und Anwendungen, die Ausgangstexte verstehen sollen (z.B. um Metadaten für die technische Dokumentation zu generieren). Die spannende Frage ist, wie können Redakteure so schreiben, dass nicht nur Menschen, sondern auch Maschinen sie besser verstehen können. Welche Verständnisfehler können sie verhindern, die nur bei Maschinen vorkommen? In anderen Worten, wie können sie maschinengerecht schreiben?
Um dieser Frage auf den Grund zu gehen, möchten wir zunächst kurz beschreiben, wie eine Maschine natürliche Sprache versteht. Dann wollen wir anhand einiger typischer Beispiele herausfinden, welche Wörter, Satzkonstruktionen oder andere Merkmale bei Maschinen Verständnisfehler verursachen. Anhand dieser Informationen wollen wir dann sehen, wie diese Fehler vermieden werden können und ggf., wenn sie nicht behebbar sind, wie man ihnen auf die Spur kommt.
Wie versteht eine Maschine die Sprache des Menschen?
Im Grunde genommen verstehen Maschinen Sprachen nicht viel anders als Kleinkinder. Kleine Kinder pauken keine Vokabellisten, lernen keine Grammatik, sondern hören den ganzen Tag lang Menschen beim Sprechen zu. Mit der Zeit erkennen sie die Bedeutung von Aussagen, sie verstehen, welche Wörter zusammen verwendet werden, wie Sätze gebildet werden.
Maschinen haben keine Seele, keine Gefühle, aber sie sind sehr gut im Rechnen. Mit Deep Learning Algorithmen lernen sie die natürliche Sprache. Sie ermitteln die Satzeinheiten (Tokens genannt) und zählen, wie oft Wörter gemeinsam verwendet werden und in welcher Reihenfolge. Genauso wie beim Kleinkind, können Sie feststellen, dass ein Satz wie ich esse eine Banane normal ist. Sie erwarten nach dem Wort essen, Wörter wie Banane, Fleisch, Kuchen und Ähnliches. Falsche Satzkonstruktionen wie ich eine essen Banane oder ein sonderbarer Objekt wie ich esse einen Stuhl sind bei mathematischen probabilistischen Modellen von Maschinen extrem unwahrscheinlich.
Worteinbettungen und Wortvektoren
In vielen KI-Modellen der natürlichen Sprache wird ein Wort durch ein Wortvektor (z.B. mit 500 Dimensionen) repräsentiert. Es sind die sogenannten Worteinbettungen (word embeddings). Diese Wortvektoren sind reine mathematische Objekte, die miteinander verglichen, addiert, subtrahiert und multipliziert werden können. So kann ein System beispielsweise herausfinden, welche Wörter zusammengehören, welche Wörter semantisch ähnlich sind und sogar Bedeutungen hinzufügen oder subtrahieren, wie die folgende Tabelle zeigt.
Ähnlichkeitsberechnungen (Ergebnis abhängig vom trainierten Modell):
| Wort | Ähnliche Wörter |
| Übersetzer | Dolmetscher, Schriftsteller, Journalist, Autor, Sprachlehrer |
| Terminologie | Fachausdrücke, Fachterminologie, Begrifflichkeit, Wortgebrauch |
Addition/Subtraktion von Bedeutungen:
| Bedeutung 1 | Bedeutung 2 | Bedeutung 3 |
| Fußball | – Tor | Tischtennis, Volleyball |
| Schreiben | + Papier | Brief, Dokument |
| Film | – Schauspieler | Dokumentarfilm |
| Auto | – Motor | Fahrrad |
| Schiff | – Meer + Luft | Flugzeug |
Bei der neuronalen maschinellen Übersetzung (NMÜ) erfolgt das Training mit Hilfe eines Transformers, einem speziellen neuronalen Netz, das aus einem Encoder und einem Decoder besteht. Der Encoder wandelt den Satz der Ausgangssprache in einen Satzvektor um, der die Bedeutung des Ausgangssatzes darstellt. Diese Bedeutung wird an den so genannten Decoder weitergegeben, der mit Hilfe eines gelernten Modells der Zielsprache die bestmögliche Übersetzung berechnet.
Mit kontrollierter Sprache Texte optimieren
In vielen Redaktionsabteilungen arbeiten technische Redakteure bereits auf der Basis eines Redaktionsleitfadens, in dem die wichtigsten Regeln für kontrolliertes Schreiben festgehalten sind. Dieser Ansatz ist durch die Produktionsprozesse für technische Dokumentation und Informationen in vielen Unternehmen begründet. Dabei kommen Redaktionssysteme wie TIM-RS, Schema ST4, COSIMA und GDS docuglobe zum Einsatz, die Informationseinheiten verwalten. Bei Bedarf stellen sie diese Einheiten zu individuellen Dokumentationen zusammen. Verschiedene Autoren erstellen diese Informationseinheiten über einen langen Zeitraum hinweg, so dass die Anwendung einheitlicher Regeln und Begriffe unbedingt erforderlich ist.
Kontrolliertes Schreiben darf nicht mit maschinengerechtem Schreiben verwechselt werden. Schreiben in kontrollierter Sprache hat eine lange Tradition. Bereits in den dreißiger Jahren wurde kontrolliertes Englisch entwickelt mit dem Ziel, leichter zu verstehen Texte zu produzieren, die von Menschen mit unterschiedlichem Bildungsstand und Kenntnissen der englischen Sprache verstanden werden können. Diese kontrollierte Sprache, die sich z.B. mit den AECMA Simplified English Regeln in den 1980er Jahren im Englischen vor allem in der Luft- und Raumfahrtindustrie stark verbreitete, war in erster Linie für Menschen gedacht. Auch in den deutschsprachigen Ländern gab es Initiativen zur Definition von kontrolliertem Deutsch. Die Tekom veröffentlichte ihr Regelwerk im Jahr 2013: Regelbasiertes Schreiben — Deutsch für die Technische Kommunikation[2].
Die wichtigsten Änderungen, die an normal geschriebenen Texten vorgenommen werden, sind in der Regel die folgenden:
- eine Bedeutung pro Wort
- Vereinheitlichung der Terminologie
- Kürzung von Sätzen, z. B. indem nicht mehr als ein Nebensatz pro Satz zugelassen wird.
- Streichung von Füllwörtern wie nur, doch, eigentlich
- Setzen von Interpunktionszeichen in Sätzen
- Erläuterung von Abkürzungen und von neuen Begriffen
Optimierter Text mit einer maschinellen Übersetzung testen
Die bisher vorgenommenen Änderungen machen einen Text für Menschen und meist auch für Maschinen verständlicher. Darüber hinaus erleichtern diese Änderungen die Wiederverwendung von Inhalten. Nun soll anhand einer automatischen Übersetzung und ihrer anschließenden Überprüfung durch fachkundige Übersetzer getestet werden, welche Probleme eine Maschine beim Verstehen oder Übersetzen dieses Textes haben könnte.
Bevor wir jedoch die Ergebnisse einer maschinellen Übersetzung bewerten, muss klar sein, dass die Qualität der einzelnen Modelle von maschinellen Übersetzungssystemen stark von den Sprachkombinationen und den Trainingsdaten abhängen. Ein kleiner Verständnistest mit dem DeepL Übersetzer, der darin besteht, einen Satz zu übersetzen und wieder zurückzuübersetzen, zeigt dies sehr deutlich:
| Sprache | Ergebnis (Deutsch > Sprache > Deutsch) |
| Englisch | Wenn die Kontrollleuchte erlischt, ist der Brühvorgang abgeschlossen. |
| Französisch | Wenn die Kontrollleuchte erlischt, ist der Brühvorgang beendet. |
| Japanisch | Das Absaugen ist beendet, wenn die Kontrollleuchte erlischt. |
| Chinesisch | Wenn die Kontrollleuchte erlischt, ist der Brühvorgang abgeschlossen. |
| Russisch | Wenn die Kontrollleuchte erlischt, ist der Brühvorgang abgeschlossen. |
| Finnisch | Wenn die Kontrollleuchte erlischt, ist der Herstellungsprozess abgeschlossen. |
Wie die Beispiele aus der folgenden Tabelle zeigen, bleiben noch eine Reihe von Problemen, die für die maschinelle Sprachbearbeitung typisch sind. Es geht im wesentlichen folgende Punkte:
- Terminologiefehler: Die Fachterminologie wird falsch oder uneinheitlich übersetzt.
- Erkennung des Kontexts, sowohl in Bezug auf den unmittelbaren Kontext (z.B. ein Fürwort bezieht sich auf ein Wort im vorangegangenen Satz) als auch in Bezug auf den allgemeinen Kontext der Aussage oder sogar auf Fragen der Allgemeinbildung.
- Genaue zutreffende Übersetzung eines Oberbegriffs wie Gerät, oder Behälter denn viele Sprachen verlangen eine präzisere Übersetzung, die vom Verwendungskontext des Oberbegriffs abhängt.
- Umsetzung von Abkürzungen und Eigennamen
- Präzise Umsetzung allgemeinsprachlicher Wörter (Nomen oder Verben)
- Zu komplexe Satzstrukturen: Sie erschweren Arbeit von NLP-Parsern. Maschinen haben dann Schwierigkeiten, die Verbindungen zwischen Wörtern zu erkennen.
- Stilistische Umsetzung von Präpositionalverben (turn off the switch oder turn the switch off).
Maschinengerecht Schreiben
Einige dieser Probleme lassen sich durch folgende Maßnahmen lösen:
- Nachtrainieren des Modells mit mehr Daten. Dies kann zum Beispiel einige stilistische, terminologische Fragen oder Fragen des Kontexts lösen.
- Umschreiben und Aufteilen komplexer Sätze. Bevorzugte Verwendung der Aktivform.
- Ersetzen von problematischen Wörtern oder Formulierungen im Text. Das kann zum Beispiel das Ersetzen eines Oberbegriffs durch einen präziseren Begriff oder das Ersetzen eines allgemeinen Verbs wie setzen durch einen präziseren wie drehen. Wenn solche Problemwörter regelmäßig erscheinen, lohnt es sich, sie zu erfassen, um sie dann vor der Freigabe eines Textes systematisch zu überarbeiten.
| Problemtyp | Ausgangssatz | Übersetzung [> richtig] |
| Kontext | Sollte es beschädigt sein, ersetzen Sie es mit einem Neuen. | (fr) Si elle est endommagée, remplacez-la par une neuve. [> il, –, le, un, neuf] |
| Kontext | Markieren Sie den Parameter %1. | Select the parameter %1. [> highlight] |
| Oberbegriff | Der Behälter enthält Gas. | The container contains gas. [> vessel] |
| Long-Tail-Wörter (seltene Wörter) | Wer trägt hier einen Snutenpulli? (Mund-Nase-Schutz-Maske) | Who is wearing a Snuten jumper here? |
| Allgemeinsprachliche Verben in Nomen | Heben Sie die Pumpe mit der Hebevorrichtung an. | Lift the pump with the lifting device. [> hoisting] |
| Allgemeinsprachliche Verben | Sie müssen die Komponente anschließen. | You must connect the component. [> attach] |
| Mehrsprachige Granularität | Dies ist ein Laden für den täglichen Bedarf. | This is a store for daily needs. [> convenience store] |
| Fehlendes Weltwissen | Der Streit über den Einsatz von Biokraftstoffen belastet die Ampel. | The disput over the use of biofuels weighs on the traffic lights. |
Mehrsprachige Begriffssysteme und Nomenklaturen
Eine besondere Schwierigkeit, mit der Maschinen umgehen müssen, sind die unterschiedlichen Begriffsstrukturen in den verschiedenen Sprachen. Jede Sprache existiert eigenständig und verwendet Wörter und Begriffe für die Realität. So unterteilt eine Sprache wie Suaheli (Swahili) Nomen in 11 Klassen wie Menschen, Pflanzen, aktive Gegenstände, kleine Tiere usw[3].
In der modernen Welt verwenden auch die Technik, die Behörden und die Staaten feste Nomenklaturen, die nicht von jeder Sprache und Nation in gleicher Weise geteilt werden. Es genügt, die einzelnen Bezeichnungen für ein Straßensystem in einem Land zu nehmen und sie in eine andere Sprache zu übersetzen, um dieses Problem zu verstehen. Noch offensichtlicher wird es bei einfachen Begriffen wie dem deutschen Begriff Fisch, der die spanische Sprache in jeweils pez für den lebenden Fisch oder pescado für den Fisch, den man auf dem Teller findet, trennt.
Tools und Methoden
Bei kleineren Dokumenten ist es kein Zaubertrick, kritische Punkte manuell zu identifizieren. Man vergleicht eine maschinelle Übersetzung mit einer Humanübersetzung Satz für Satz und bewertet die Abweichungen. Natürlich müssen nicht unbedingt alle Unterschiede Fehler sein.
Anders sieht es aus, wenn Dokumente oder Korpora, die aus mehreren zehntausend Wörtern bestehen, optimiert werden sollen. Hier wären andere Ansätze nötig, um mit möglichst geringem Aufwand potenzielle Problemfälle zu erkennen.
Hierzu können einige Verfahren der Computerlinguistik von Nutzen sein. Statistische Informationen über die Häufigkeit einzelner Wörter oder die Häufigkeit des gemeinsamen Auftretens von Wörtern (Kookkurrenzanalyse) zusammen mit Informationen über grammatikalische Kategorien (Part-of-Speech Tagging, POST) helfen dabei, gezielt potenzielle Probleme aufzuspüren. Das können beispielsweise die gezielte Suche nach häufigen Handlungsverben sein, die sowohl als Verb als auch als Verbalsubstantiv wie Spannvorrichtung oder Hebevorrichtung in Texten vorkommen.
Oder es lassen sich häufig verwendete Verben aufspüren, die in bestimmten Situationen anders übersetzt werden sollten, wie beispielsweise öffnen oder schließen. Hier empfiehlt es sich, für solche allgemeine Wörter die Anzahl der Varianten einzuschränken und sie zu standardisieren.
Man muss kein ausgebildeter Computerlinguist sein, um diese linguistische Recherche durchzuführen. Es gibt einige sehr gute frei verfügbare Programme wie AntConc, und TagAnt[4], die Informationen wie Wortart, Häufigkeit oder Kookkurrenz aus größeren Corpora liefern.
Verbleibende Fehlerarten
Die Fehler, die durch maschinengerechtes Schreiben nicht verhindert werden konnten, gehören zwar zu Kategorien wie Terminologie, Allgemeinwörter oder Kontext, aber sie sind meist spezifisch für die vom Unternehmen produzierten Inhalte. Die gute Nachricht ist, dass dank Deep Learning, Big Data und immer leistungsfähigeren Prozessoren die Sprachmodelle immer besser und die Fehler immer geringer werden.
Die Hauptaufgabe besteht nun darin, diese verbleibenden Probleme zu erfassen, um sie nach einer Übersetzung schnell zu entdecken. Damit wird nicht nur das Post-Editing maschineller Übersetzungen (MTPE) effizienter, sondern auch zuverlässiger, denn es wird gezielt nach Fehlern gesucht, die nur Maschinen machen. Dies unterstützt die Anforderungen der Norm DIN ISO 18587 für Post-Editing.
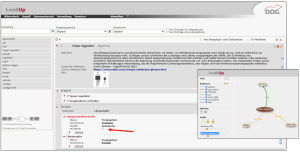
Wo sollen diese Information erfasst werden? Sie können in einem Redaktionsleitfaden oder in Checklisten erfasst werden. Wenn es sich um terminologierelevante Informationen handelt, können sie in einem Terminologieverwaltungssystem (TVS) wie LookUp von der D.O.G. GmbH erfasst werden. Spezielle Attribute, die diese Fehler als typisch maschinelle Übersetzungsfehler identifizieren, können in das TVS eingegeben werden (Siehe Screenshot von LookUp).
Darüber hinaus können solche Terminologiedatenbanken auch Relationen zu Kontextbegriffen oder Kontextbenennungen enthalten, die maschinenlesbar sind. Eine Qualitätssicherungssoftware wie ErrorSpy kann diese Informationen (Attribute und Kontextrelationen) interpretieren und so für das Post-Editing gezielt nach durch Maschinen verursachte Fehlern suchen.
Maschinen brauchen Menschen
Intelligente Systeme, die natürliche Sprache verstehen, werden zusehends besser. Riesige Mengen an Trainingsdaten und extrem leistungsstarke Computersysteme verschieben die Grenzen der KI immer weiter hinaus. Laut einem Bericht des Marktforschungsunternehmens CSA Research[5], sind neue Entwicklungen wie die Responsive Machine Translation (reaktive maschinelle Übersetzung) dabei, die Ergebnisse der NMÜ noch weiter zu optimieren. Sie kombinieren Sprachmodelle mit Metadaten über Kontext und Nutzungsszenarien und ermöglichen dadurch eine dynamische Anpassung der Übersetzung an die Inhalte.
Vor allem bei Übersetzungen liefern neuronale maschinelle Übersetzungssysteme Ergebnisse, die bereits bis zu einem gewissen Grad mit Humanübersetzungen mithalten können. Natürlich gibt es noch viele schwerwiegende Fehler, aber der Trend ist eindeutig. Das beunruhigt zwar die traditionellen Übersetzer, bedeutet aber auch neue Chancen und neue Herausforderungen. Denn diese Systeme hängen von der Qualität der Trainingsdaten und der Evaluierung der Ergebnisse ab. Dafür brauchen sie Menschen mit entsprechendem Know-how, Menschen, die verstehen, wie KI funktioniert, die wissen, wie man maschinenfähige Texte schreibt und die Ergebnisse maschineller Übersetzungen auswertet und was man tun kann, um sie zu optimieren.
[1] Erster Text generiert über https://smodin.io/de/schriftsteller. Zweiter Text aus: https://de.textmaster.com/blog/neuronale-maschinelle-ubersetzung-was-sie-wissen-mussen/
[2] https://www.tekom.de/die-tekom/publikationen/fachbuecher/detail/deutsch-fuer-technische-kommunikation
[3] http://www2.iath.virginia.edu/swahili
[4] https://www.laurenceanthony.net/software
[5] https://csa-research.com/Blogs-Events/Blog/responsive-MT-Test